
Introduction to Neural Networks
Neural networks are a subset of machine learning, inspired by the structure and function of the human brain. They comprise layers of interconnected nodes, or “neurons,” which process data in a manner similar to how the human brain interprets stimuli. Each neuron in a neural network receives input from multiple data points, applies a mathematical operation to this input, and produces an output that can be passed to subsequent layers. The architecture of neural networks typically consists of an input layer, one or more hidden layers, and an output layer.
The input layer serves as the entry point for the data, while the hidden layers are responsible for interpreting the patterns and relationships within the data through numerous transformations. The final output layer generates predictions or classifications based on the processed information. Each connection between neurons, referred to as a “weight,” is adjusted during the training process to enhance the model’s accuracy in making predictions.
Neural networks utilize specific terminology essential for understanding their functioning. Terms such as “activation function,” which determines whether a neuron should be activated, and “backpropagation,” a method for optimizing the weights, are fundamental in the training process. The significance of neural networks has expanded in the realms of artificial intelligence and machine learning, enabling advancements in areas such as image and speech recognition, natural language processing, and autonomous systems.
Furthermore, neural networks have proven exceptionally effective in handling vast amounts of data and complex pattern recognition, making them indispensable tools in modern technology. As a cornerstone of many AI applications, their ability to learn from data and improve functionality over time marks a pivotal development in the advancement of intelligent systems.
The Learning Process Explained
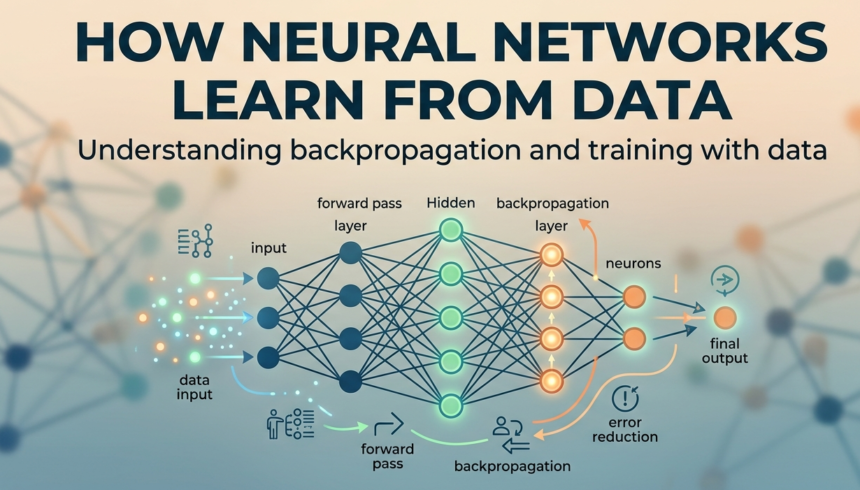
Neural networks learn from data through a sophisticated process that involves various algorithms designed to optimize performance. The core of this learning process can be understood through two main concepts: forward propagation and backpropagation.
Diving into forward propagation, this is the initial phase where input data is fed into the network. Each neuron processes the inputs it receives, applying a weighted sum followed by an activation function. The output of one layer becomes the input for the next, ultimately leading to the final output of the network. This output is compared to the actual outcome or target value, allowing the network to calculate the loss or error.
The subsequent step in the learning process is backpropagation, which is essential for the adjustment of weights within the neural network. Once the network has determined the error in its predictions through forward propagation, it needs to minimize this error. Backpropagation accomplishes this by computing the gradient of the loss function with respect to each weight by the chain rule. This gradient indicates the direction in which the weights need to be adjusted to improve accuracy. Following the calculation of these gradients, a specific optimization algorithm, such as Stochastic Gradient Descent (SGD) or Adam, updates the weights iteratively. This adjustment continues over numerous epochs—that is, cycles through the training data—until the network achieves satisfactory performance.
Ultimately, the balance between forward propagation and backpropagation is what enables neural networks to effectively learn from data. Through continuous adjustments to their weights based on the input data and corresponding errors, neural networks are able to refine their models and enhance predictive accuracy. This intricate learning process underlines how neural networks harness data to improve their decision-making capabilities, thus making them powerful tools in various applications across fields such as image recognition, natural language processing, and beyond.
Data Representation in Neural Networks
The effectiveness of neural networks in learning from data greatly depends on how the data is represented and prepared for processing. One critical step in this preparation involves feature extraction, which refers to the process of identifying and isolating relevant information from raw data. By selecting informative features, neural networks can operate more efficiently. For instance, in image recognition tasks, extracting features such as edges or colors can significantly enhance the model’s ability to generalize from training examples.
Another important aspect to consider in data representation is data normalization. This process involves transforming the input data to a common scale, which can expedite convergence during the training of neural networks. Normalization techniques, such as Min-Max scaling or Z-score standardization, help in minimizing biases caused by different scales across numerical features. When data is normalized, neural networks can adjust their weights more effectively, resulting in reduced training times and improved performance.
In supervised learning scenarios, the importance of labeled data cannot be overstated. Labeled data provide the necessary information for the neural networks to learn patterns effectively. Each input data point must be paired with a corresponding label that guides the network during the training phase. Accurate labeling contributes to the model’s learning and its subsequent capability to make predictions on unseen data. In situations where labeled data is scarce or expensive to obtain, semi-supervised and unsupervised approaches can be considered, but these methods often require a strategic understanding of the underlying data structure.
Overall, the representation of data plays a crucial role in the successful training of neural networks. Adequate feature extraction, normalization, and the availability of labeled data influence the learning process and ultimately determine the effectiveness of the model in real-world applications.
Training Neural Networks: Techniques and Strategies
Training neural networks involves various techniques and strategies that enhance their ability to learn from data efficiently. One of the fundamental concepts in this realm is the idea of epochs, which refers to the number of times the entire training dataset passes through the neural network. Each epoch allows the model to adjust its weights based on the computed errors, incrementally improving its performance. However, merely increasing the number of epochs does not guarantee better learning, as it can lead to overfitting, where the model performs exceptionally well on training data but poorly on unseen data.
Another critical factor in training neural networks is the size of the batches used during the training process, commonly referred to as batch size. Smaller batch sizes can lead to more frequent updates to the model’s parameters, resulting in a noisier but potentially more effective optimization process. Conversely, larger batch sizes can smooth out the learning curve, providing more accurate estimations of the gradient at the cost of computational efficiency and increased risk of local minima.
Additionally, during the training phase, it is essential to implement a training/validation split. This technique involves partitioning the dataset into separate subsets for training the model and validating its performance. This practice ensures that the model can generalize well on better datasets, reducing the likelihood of overfitting while allowing practitioners to monitor and adjust the learning process.
Regularization methods are also vital in maintaining a well-performing neural network. Techniques such as dropout, L1 and L2 regularization, and data augmentation introduce various constraints to the learning process, helping to manage overfitting by forcing the network to learn more robust features rather than memorizing the training data. Together, these strategies form a comprehensive approach to the training of neural networks, ensuring that they are both effective and efficient in learning from data.
The Role of Activation Functions
In the context of neural networks, activation functions are pivotal for introducing non-linearity into the model. Without these functions, a neural network would behave like a linear regression model, limiting its complexity and functionality. Essentially, activation functions dictate whether a neuron should be activated or not, influencing the output based on its weighted input.
One of the most commonly used activation functions is the sigmoid function. This function maps any input value to a range between 0 and 1, making it particularly useful for binary classification problems. Its S-shaped curve allows for smooth gradient changes, which is essential during the backpropagation process. However, the sigmoid function can suffer from the vanishing gradient problem, particularly when neurons are in deep layers, leading to slow convergence during training.
Another popular activation function is the Rectified Linear Unit (ReLU). The ReLU function outputs the input directly if it is positive; otherwise, it returns zero. This simplicity allows models to converge faster, as it does not saturate like the sigmoid function does. Furthermore, ReLU helps to reduce the likelihood of the vanishing gradient problem, making it a prevalent choice in deep learning architectures. However, it can also lead to the dying ReLU problem, where neurons can become inactive and stop learning entirely.
Softmax is another activation function often used in the output layer of multi-class classification problems. Softmax converts the raw output scores of a neural network into normalized probabilities that sum to one, allowing the model to make probabilistic predictions about multiple classes. This function is instrumental in scenarios where one must evaluate the likelihood of different outcomes, thereby aiding decision-making processes significantly.
Error Calculation and Optimization Algorithms
Neural networks rely significantly on error calculation to refine their learning processes. The error, or loss, measures how well the neural network’s outputs align with the actual target values. This is primarily quantified through loss functions, which define the discrepancy between the predicted and true outputs. Popular loss functions include Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks. The choice of the loss function is pivotal as it directly influences the performance of the neural network.
Once the error is calculated, optimization algorithms are employed to minimize this error across multiple iterations during training. One of the fundamental optimization techniques is gradient descent, which involves calculating the gradient of the loss function with respect to each weight in the network. By following the negative direction of the gradient, the algorithm updates the weights to reduce the error iteratively. Though effective, standard gradient descent can be slow and has challenges such as falling into local minima.
To address the limitations of basic gradient descent, several advanced optimization algorithms such as Adam and RMSprop have surfaced. Adam, short for Adaptive Moment Estimation, combines the benefits of both momentum and RMSprop to adaptively change the learning rate for each parameter based on past gradients. This ensures a more dynamic and efficient convergence towards the optimal solution. Similarly, RMSprop adapts the learning rate based on the average of recent gradient magnitudes, preventing drastic updates and promoting more stable training. These optimization techniques are critical in improving the training efficiency of neural networks, facilitating them to learn from complex data effectively.
Evaluating Neural Network Performance
Evaluating the performance of a neural network is crucial for understanding its effectiveness and accuracy in making predictions. Several metrics provide valuable insights into how well a model performs, including accuracy, precision, recall, F1 score, and the confusion matrix. Each of these metrics plays a unique role in performance evaluation.
Accuracy is the simplest metric, representing the proportion of correctly predicted instances over the total number of instances. Although it offers a quick overview, accuracy can be misleading, especially in cases of class imbalance, where the number of instances in one class significantly exceeds that of another.
To address this issue, precision and recall are often used in tandem. Precision calculates the ratio of true positive predictions to the total positive predictions made, thus indicating the accuracy of the positive class. Recall, or sensitivity, measures the proportion of true positives to the total actual positives, which reflects the ability of the model to capture the relevant class.
The F1 score combines both precision and recall into a single metric, offering a comprehensive performance measure by balancing both aspects. It is particularly useful when the datasets are imbalanced, providing a more holistic view of the model’s predictive power.
Additionally, the confusion matrix serves as a visual representation of the performance of the neural network, detailing the true positive, true negative, false positive, and false negative counts. This matrix helps stakeholders ascertain not only the error rates but also the types of errors being made by the model.
Incorporating these metrics into the evaluation process allows for an extensive understanding of neural network performance. By carefully interpreting these indicators, practitioners can make informed decisions regarding model optimization and selection, ultimately enhancing the model’s efficacy in real-world applications.
Challenges in Neural Network Learning
Training neural networks presents several challenges that can significantly impact their performance and overall accuracy. One of the primary issues encountered is the phenomenon known as vanishing gradients. This occurs when the gradients of the loss function diminish as they are back-propagated through the layers of the network, leading to minimal updates in the weights of early layers. As a result, the network struggles to learn from the data effectively, particularly in deep architectures, where many layers are involved. To mitigate this issue, techniques such as using ReLU (Rectified Linear Unit) activation functions and initializing weights appropriately can be implemented, allowing for better gradient flow.
Another common challenge is data imbalance, wherein certain classes in the training dataset are underrepresented compared to others. This can cause neural networks to become biased towards the more prevalent classes, thus reducing their ability to generalize and accurately predict outcomes for the minority classes. Potential solutions for addressing data imbalance include techniques such as over-sampling the minority class, under-sampling the majority class, or employing synthetic data generation methods to create more balanced datasets.
Additionally, the requirement for large datasets is another notable hurdle in neural network learning. Deep learning models thrive on vast amounts of data to recognize patterns and improve predictive accuracy. However, the lack of sufficient data can lead to overfitting, where the model performs well on the training set but poorly on unseen data. To alleviate this concern, techniques such as data augmentation, which generates new training samples from existing ones, can be utilized. Moreover, transfer learning can be employed, allowing a neural network pre-trained on a large dataset to be fine-tuned on smaller datasets, aiding in the extraction of meaningful features without the need for excessive data.
Future of Neural Networks and Learning from Data
The future of neural networks continues to exhibit immense potential for transforming various sectors through advanced data learning methodologies. As technology evolves, neural networks are set to become increasingly sophisticated, enabling them to process and learn from data in more nuanced ways. Key trends in this field suggest significant advancements in architectural designs, including deeper and more complex networks. These developments aim to improve the efficiency and accuracy of neural networks, thereby enhancing their learning capabilities.
One prominent trend is the integration of unsupervised and semi-supervised learning techniques. This shift allows neural networks to autonomously identify patterns and correlations within unannotated data, thus reducing the reliance on labeled datasets. This approach is crucial, as it can significantly expedite the training process and increase the applicability of neural networks across various domains, such as healthcare, finance, and autonomous systems.
Moreover, enhancements in hardware performance, such as the development of specialized chips for deep learning, will facilitate faster model training and execution. This hardware evolution enables neural networks to scale up, making real-time data processing feasible in complex applications. In domains such as climate modeling and personalized medicine, such capabilities promise to revolutionize our understanding and interaction with vast amounts of data.
Emerging applications will likely include advancements in natural language processing, computer vision, and robotics. As researchers continue to refine their understanding of how neural networks learn, we can anticipate their expansion into areas that demand rapid decision-making and analysis, such as fraud detection or predictive maintenance in manufacturing. Overall, the trajectory of neural networks reveals a commitment to not only refining learning processes but also making them more accessible and powerful for future innovations.






